
Chainlit
AI-assisted overview of Chainlit
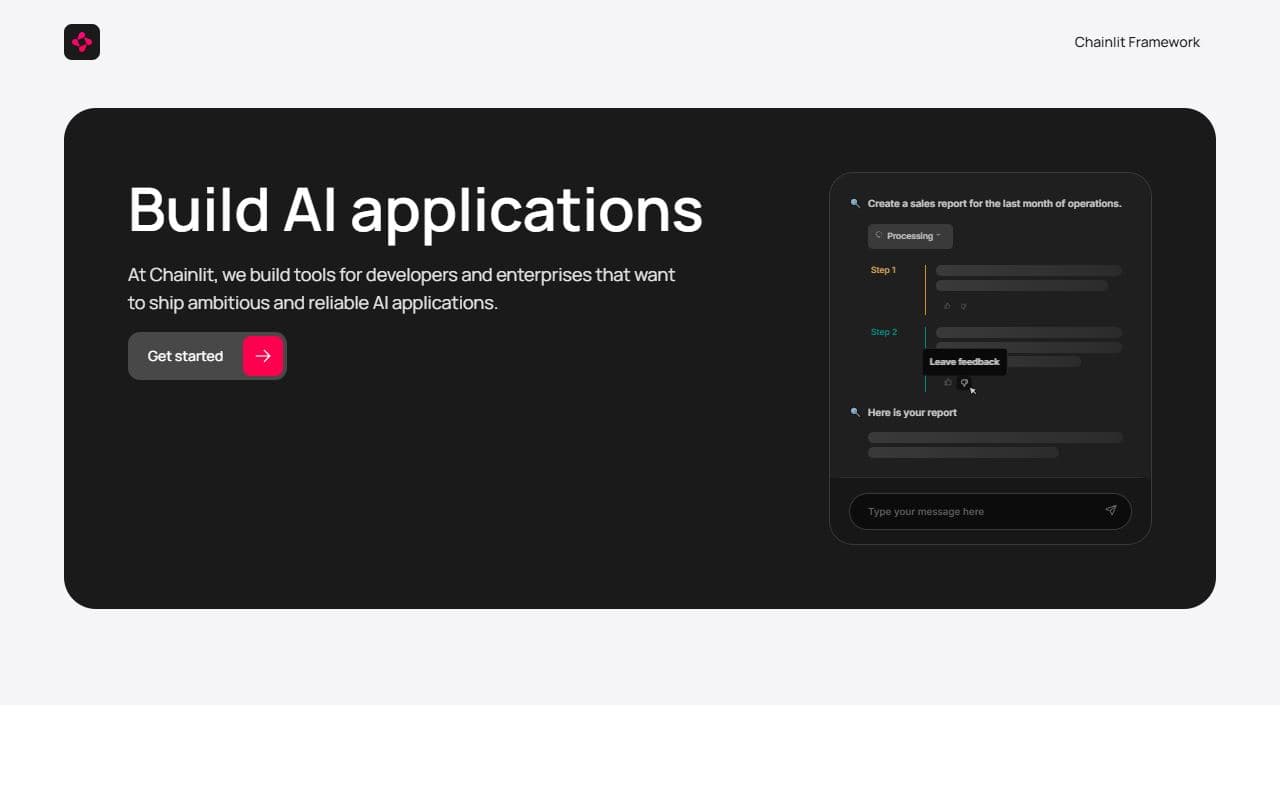
Chainlit is an open-source framework specifically engineered to accelerate the development of conversational AI interfaces, agent demonstrations, and internal Large Language Model (LLM) applications.
Positioned as a key utility in the AI development toolkit, it offers the foundational components necessary for rapid prototyping and deployment of interactive AI systems. This framework is designed to abstract away common complexities, enabling developers to quickly transition from an initial concept to a functional AI application, thereby enhancing productivity and shortening development cycles for AI-driven projects. The framework's open-source nature ensures broad accessibility and encourages collaborative contributions, fostering a dynamic environment for continuous improvement and innovation within the AI community. It proves particularly useful for engineers and teams focused on showcasing AI agent capabilities or integrating sophisticated LLM functionalities into enterprise-level internal tools. By offering a streamlined approach to building AI applications, Chainlit serves as an efficient choice for projects demanding swift iteration and deployment in the conversational AI and LLM application domains, solidifying its role as a fundamental utility for creating engaging and operational AI experiences.
This summary was generated from available directory data and may be incomplete. Verify current details on the official website before making a decision.
AI-assisted capability summary
- Operates as an open-source framework
- Facilitates the creation of conversational AI interfaces
- Supports the development of AI agent demonstrations
- Enables building internal Large Language Model (LLM) applications
- Designed for rapid application development
- Provides utilities for AI application construction
- Accessible without cost
Potential use cases
Developing interactive user interfaces for conversational AI solutions
Creating proof-of-concept demonstrations for AI agents
Building internal business applications powered by Large Language Models
Rapidly prototyping new conversational AI features or products
/// EVALUATION NOTES
What to verify before using Chainlit
ClawSites is the discovery layer, not the final approval. Use these checks to turn this listing into a small, evidence-based product test.
Workflow fit
Define the exact utilities job before comparing features. A good test has a clear input, output, and pass condition.
Access and permissions
Confirm whether the product needs a browser session, local runner, API key, inbox, repository, database, or payment access.
Human approval
Find the point where a person can inspect the result and stop an irreversible action such as sending, spending, deleting, or deploying.
Evidence after a run
Prefer logs, citations, screenshots, diffs, traces, or status history that let another person understand what happened.
| Directory category | Utilities |
|---|---|
| Pricing signal | Unknown |
| Recorded status | online |
| Structured context | 7 AI-assisted capability notes · 4 potential use cases · 8 AI-assisted discovery tags |
A practical three-step test
- 1Choose one reversible task. Write down the expected result before connecting sensitive systems.
- 2Limit access. Start with sample data, read-only permissions, or a test account.
- 3Save the evidence. Compare output quality, review effort, failure behavior, and time saved.